


Uncertain Climate Predictions and Certain Energy Progress – Part 2
The greater uncertainties of climate prediction.
In his book Unsettled: What Climate Science Tells Us, What It Doesn’t, and Why It Matters, Steven Koonin sets out how the computer “climate model” programs – the programs used to make predictions about climate change -- actually work. How they work, and their inherent limits, is something popular media rarely explains in any detail, but understanding it is essential to realizing how uncertain predictions of temperature increases are.
First, there are a huge number of confounding factors that enter into climate changes. As Koonin writes:
Future emissions, and hence human influences on the climate, will depend upon future demographics, economic progress, regulation, and the energy and agricultural technologies in use … Because of the great uncertainties about the decades to come, instead of making precise predictions of future concentrations, the IPCC [Intergovernmental Panel on Climate Change] created a set of scenarios. They have the rather complicated name of “Representative Concentration Pathways,” or RCPs. These are meant to span a plausible range of possibilities for population, economy, technology, and so on … Global real GDP is assumed to grow strongly through the twenty-first century in all scenarios, by a factor of six in the higher-emitting scenarios, but by a factor of ten in the lower-emitting scenarios, presumably because a more prosperous world is able to place a higher priority on environmental matters. Since GDP grows by a larger multiple than population in all scenarios, the world in 2100 is projected to be more prosperous on a per capita (that is, per person) basis in any future (a detail often omitted from discussions of model results) … A recent analysis of emissions from 2005 to 2017 shows that high-emissions scenarios are increasingly implausible because of slower economic growth through 2040 and reduced coal use through the end of the century.
But even putting the difficulty of accurately predicting future demographics, economic progress, regulation, and changes in energy and agricultural technologies in use, there’s a fundamental limitation of computer models designed to predict climate change embedded in their parameters. As Koonin writes:
All but the simplest computer models of the climate begin by covering the earth’s atmosphere with a three-dimensional grid, typically ten to twenty layers of grid boxes stacked above a surface grid of squares that are typically 100 km × 100 km (60 miles × 60 miles), as shown in Figure 4.1. But because the height of the atmosphere that needs to be modeled is comparable to the size of one surface grid square, the layered boxes atop the grid are much more like pancakes than the cubes shown in the figure (more about that shortly). The grid covering the oceans is similar, but with smaller surface grid squares, typically 10 km × 10 km (6 miles × 6 miles), and more vertical layers (up to thirty). With the entire Earth covered this way, there are about one million grid boxes for the atmosphere and one hundred million grid boxes for the ocean. Grid in place, the computer models use the fundamental laws of physics to calculate how the air, water, and energy in each box at a given time move to neighboring grid boxes at a slightly later time; this time step can be as small as ten minutes. Repeating this process millions of times over simulates the climate for a century (just over five million times if the time step is ten minutes). These many time steps in a simulation can take months of computer time on even the world’s most powerful supercomputers; the amount depends upon the number of grid boxes and how many time steps are taken, as well as the sophistication of the model’s description of what goes on in the grid boxes (its “physics”).
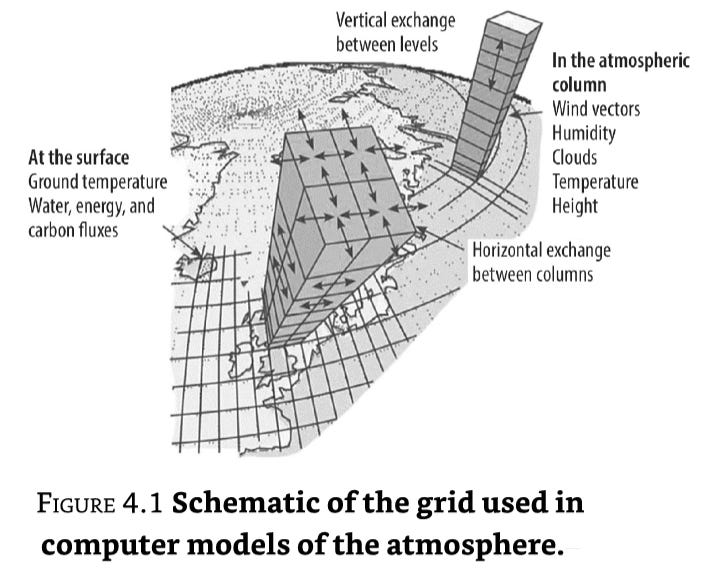
And here Koonin makes a key point:
One major challenge is that the models use only single values of temperature, humidity, and so on to describe conditions within a grid box. Yet many important phenomena occur on scales smaller than the 100 km (60 mile) grid size (such as mountains, clouds, and thunderstorms) and so researchers must make “subgrid” assumptions to build a complete model. For example, flows of sunlight and heat through the atmosphere are influenced by clouds. They play a key role—depending upon their type and formation, clouds will reflect sunlight or intercept heat in varying amounts. Physics tells us that the numbers and types of clouds present in each of the layers of atmosphere above a grid square (the stacked boxes) will generally depend upon conditions there (humidity, temperature, and so on). Yet as illustrated by Figure 4.2, changes and differences in clouds occur on a much smaller scale than that of a grid box, and so assumptions are necessary.
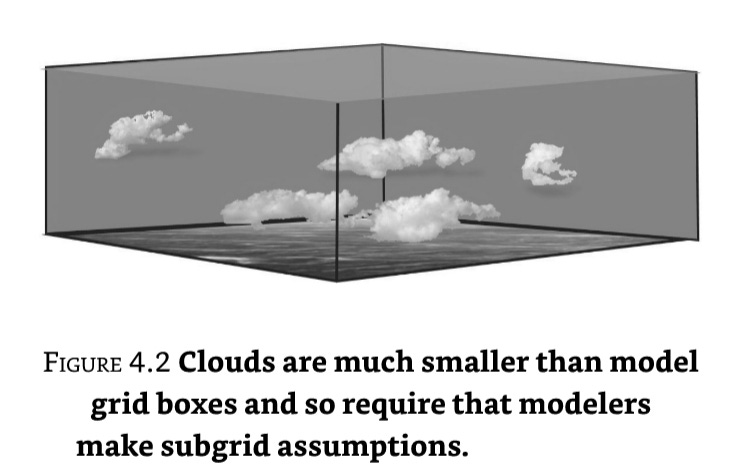
While modelers base their subgrid assumptions upon both fundamental physical laws and observations of weather phenomena, there is still considerable judgment involved. And since different modelers will make different assumptions, results can vary widely among models. This is not at all an unimportant detail, since ordinary fluctuations in the height and coverage of clouds can have as much of an impact on flows of sunlight and heat as do human influences. In fact, the greatest uncertainty in climate modeling stems from the treatment of clouds.
Computer climate modelers don’t make the grid sizes smaller to account for cloud formation in better detail because doing so would dramatically increase the computations involved, to the point of impracticability. As Koonin writes:
[A]side from the number of boxes, a finer grid introduces another complication: Any computation is only accurate if things don’t change too much over one time step (that is, don’t move more than one grid box). So if the grid is finer, the time step has to be smaller as well, meaning even more computer time will be required. As an illustration, a simulation that takes two months to run with 100 km grid squares would take more than a century if it instead used 10 km squares. The run time would remain at two months if we had a supercomputer one thousand times faster than today’s— a capability probably two or three decades in the future … Pancake boxes generally make for a more accurate simulation where the atmosphere is flowing in layers, for example in the upper parts of the stack (there’s a reason the high-altitude atmosphere is called the stratosphere). But these flat boxes become a problem in the atmosphere below 10 km (6 miles), where turbulent weather happens. Upward flows of energy and water vapor (think thunderhead clouds) occur over areas much smaller than the 100 km (60 miles) of our grid. This is particularly troublesome in the tropics, where upward flows are important in lofting energy and water vapor from the ocean surface into the atmosphere. In fact, the flow of energy carried into the atmosphere by evaporation of the ocean waters is more than thirty times larger than the human influences shown back in Figure 2.4 [displayed in the previous essay]. So subgrid assumptions about this “moist convection”—how air and water vapor move vertically through the flat grid boxes—are crucial to building accurate models.
But assumptions are just that – assumptions. And those assumptions contain multiple assumptions within them. As Koonin writes:
The last remaining step is to “tune” the model. Each subgrid assumption has numerical parameters that have to be set—somehow. Cloud cover and convection are only two examples out of dozens. How much water evaporates from the land surface depending upon the soil properties, plant cover, and atmospheric conditions? How much snow or ice is on the surface? How do ocean waters mix? … In any event, it is impossible— for both practical and fundamental reasons— to tune the dozens of parameters so that the model matches the far more numerous observed properties of the climate system. Not only does this cast doubt on whether the conclusions of the model can be trusted, it makes it clear that we don’t understand features of the climate to anywhere near the level of specificity required given the smallness of human influences. Among the most important things that a model has to get right are “feedbacks.”
One of these crucial “feedback” mechanisms involves how as temperatures rise, they tend to create more water vapor, which in turn creates more clouds, which then reflect more heat back into space:
Another example of a feedback is that as the atmosphere warms, it will hold more water vapor, which further enhances its heat-intercepting ability. But more water vapor will also change the cloud cover, enhancing both heat interception (high clouds) and reflectivity (low clouds). On balance, the reflectivity wins, and the net cloud feedback somewhat diminishes the direct warming.
But because the computer models use grids of a size too large to adequately account for cloud formation, those models are inherently flawed to a significant degree (no pun intended).
As Peter Wallison points out, the inherent defects in these computer models may be relevant to any required disclosure by fossil fuel companies of “all material facts” regarding their influence on climate change:
The Biden administration is continuing its efforts to discourage investment in fossil fuels, now enlisting the help of the Securities & Exchange Commission with a massive new regulation requiring public companies to disclose their “climate risks.” … However, the SEC’s standards for disclosure—all material facts, including those that make the facts disclosed not misleading—will not necessarily advance the Administration’s climate objectives … Let’s start with facts about the alleged dangers of fossil fuels. It might be risky for a company to include in its prospectus or other reports the computer-generated models that the media usually credits when it describes the dangers of future climate change. These reports are published by the International Panel on Climate Change (IPCC) and suggest that the continued emission of carbon dioxide has caused a warming Earth. But many scientists regard these models as grossly inaccurate and misleading.
So what happens when these predictive computer models are run backwards, to see if, based on the same parameters they use going forward, they accurately describe temperature changes in the past, going backwards? That will be the subject of the next essay.
Links to all essays in this series: Part 1; Part 2; Part 3; Part 4; Part 5; Part 6; Part 7; Part 8; Part 9.