


Origami, Ourselves – Part 3
The DNA computer.
As we explored in previous essays, our bodies use proteins that self-assemble themselves under the influence of physical laws. But how do they move around so they can accurately replicate our DNA to form our bodies?
First, let’s understand how long the codes are that proteins have to replicate. As Raghuveer Parthasarathy writes in So Simple a Beginning: How Four Physical Principles Shape Our Living World:
[Y]our genome [is] as a database of 20,000 protein-coding genes, but it’s also a physical object, a series of A-T and C-G nucleotide base pairs that are the rungs of DNA’s double-helical ladder, taking up physical space. Let’s consider nucleotides first, then actual space … The human genome isn’t 24 million base pairs long, however: it’s 3 billion base pairs … We started this section with the question, “How big is your genome?” and gave a biologically accurate but physically unsatisfying answer: 3 billion base pairs. How big is this? Each of the two copies of your genome, housed in nearly all of your cells, would span a meter (3 feet) in length if laid out in a line … [Y]our DNA isn’t one unbroken strand but rather is divided into 23 chromosomes. (Nearly all of your cells have 46 fragments grouped in pairs, from each of the two copies of your genome. Exceptions are egg and sperm cells, which have one copy of your genome, and red blood cells, which in humans and other mammals lack DNA.) … Much of your DNA is wrapped around little spools about 10 nanometers in diameter, made of proteins called histones. Ten nanometers is much smaller than the [] length of DNA, so this wrapping requires a lot of force, provided in large part by electrical attraction between the DNA, which is negatively charged, and the positively charged outer surface of the histones … Once again, we find self-assembly at work: the physical attributes of DNA and histone proteins, especially their charge and shape, enable them to craft themselves into a well-defined, functional structure. Nearly two turns of DNA, or about 150 nucleotide base pairs, are wound around each spool. The span in between the spools varies in length, between 20 and 90 base pairs, and the whole assembly is evocatively referred to as “beads on a string.”
This pushing and pulling forces move everything in our bodies around, including viruses:
In a double-stranded DNA virus, the bent, squished polymer pushes on the virus’s shell, or capsid, trying to stretch out. When the capsid is opened, for example, when the virus infects a cell, this internal pressure helps propel the DNA into its cellular target … Capsid opening is naturally triggered when a virus encounters particular proteins on the surface of its target cell … To get a more intuitive sense of the mechanical feats performed by these viruses, biophysicist Rob Phillips suggests envisioning 500 yards of Golden Gate Bridge suspension cable crammed into the back of a FedEx delivery truck. These huge internal pressures are valuable for the virus, helping it launch its DNA into a targeted cell where it will be replicated, initiating the generation of new viruses.
Now back to our proteins. How do those proteins move things around in our bodies so our DNA instructions can be replicated?
There isn’t … a machinery that directly reads the DNA code and makes the corresponding protein. A molecule called RNA (ribonucleic acid) acts as an intermediary. RNA, as its name might suggest, is similar to DNA. RNA is also a chain composed of any of four nucleotide units, three of which (A, C, and G) are the same as those in DNA and the fourth of which (U, uracil) is similar to DNA’s T (thymine). A protein machine called RNA polymerase binds to a “promoter” sequence of DNA and then steps along the double helix like the slider on a zipper, spreading the two strands apart, reading the nucleotide sequence of one of the strands, called the template strand, and constructing a single- stranded chain of RNA. The process, which copies information from one form (DNA) to another (RNA), is called transcription, analogous to the transcription of spoken words into text or handwritten notes into type … We can’t understand DNA without understanding its physical properties. Shape, structure, and mechanics are inextricably tied to biological function. This statement isn’t true just for DNA but for all of nature’s biomolecules—a recurring theme throughout biophysics … How is it that a mere 20,000 genes encodes the complexity of you? How do just 20,000 proteins—in other words, 20,000 tools or 20,000 components—perform the dazzling array of tasks that you’re capable of, from growing to breathing to reading to reproducing? … Here we encounter a more abstract manifestation of self-assembly, as molecular activities weave themselves into regulatory circuits that make every creature a biological computer. To see what this means, we start with the notion of turning genes on and off. A cell, or a whole organism, can control when and whether to actually make use of any given gene—in other words, whether its string of As, Cs, Gs, and Ts is read by the machinery that transforms a DNA sequence into an RNA sequence into a protein. This control can be influenced by the external conditions that the cell or organism is experiencing, letting it activate or deactivate particular genes in response. Even before understanding regulation in detail, you could infer that something like this must exist from the fact that your body is composed of very different types of cells, though each contains a copy of the same DNA. The genomes inside a neuron, a skin cell, and a mucus-secreting cell that lines your gut are all identical. These cells, however, don’t look the same, don’t perform the same activities, and are not synthesizing the same set of proteins. Genes for proteins that create mucus must be dormant in neurons; genes for proteins that adhere tightly to neighboring cells must be active in your skin; your secretory cells must ignore the genes responsible for sending long-distance electrical signals. Somehow, it must be possible to turn genes “on” and “off.” Let’s see how this control is made possible.
Parthasarathy uses the relatively simple example of a bacterium to show how the basic process works:
Imagine you’re a bacterium. You like to eat sugars, but you need to make sugar-digesting proteins to do this. You’d prefer to make more such proteins if you encounter sugar, and you’d rather not waste energy making these proteins if there’s no sugar around. How can you do this? We illustrate with an actual sugar, lactose, and the regulatory machinery found in the bacterium E. coli, which is very similar to machineries used throughout the living world. A gene called lacZ encodes part of the lactose consumption machinery … E. coli also makes a protein called the lac repressor, which binds to another stretch of DNA upstream of the lacZ gene. When the lac repressor (red) is DNA-bound, RNA polymerase can’t attach and the lacZ gene is not expressed … DNA and proteins are physical objects, with particular structures that guide how they work. The binding between the lac repressor and DNA has a particularly striking arrangement. The specific sets of nucleotides that the lac repressor recognizes are spaced farther apart than the repressor’s width. The protein must therefore loop the DNA into a tight circle, about 10 nanometers in diameter. Recall, however, that DNA is very stiff. Left alone, it will be quite straight over distances of about 100 nanometers. Like a circus strongman flexing an iron bar, the lac repressor bends the DNA. The looped DNA interferes with the normal binding of RNA polymerase, preventing the readout of the genes for lactose-digesting proteins … It’s a clever system, especially for a brainless creature a thousandth of a millimeter in size.
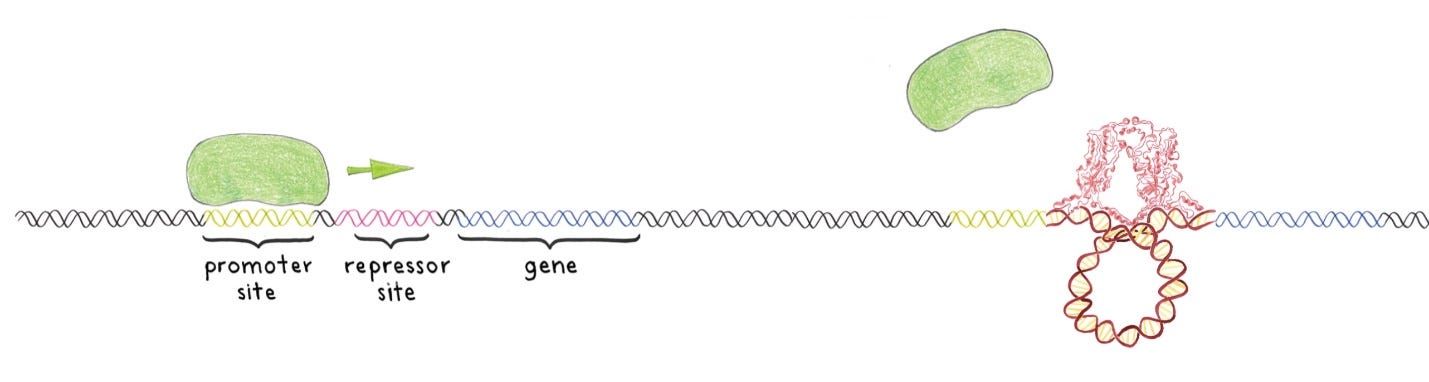
“Transcription factors” are proteins that control the transcription rate of genetic information from DNA to messenger RNA, by binding to a specific DNA sequence:
Transcription factors are themselves proteins, and so are encoded by genes. We have a lot of them—it’s not known exactly how many, but it’s thought that the human genome contains over 1500 genes for transcription factors. Recall that we have only about 20,000 protein-coding genes. A sizable fraction of our genetic instruction set, in other words, is made up of the brakes and levers that regulate the readout of those instructions … A device that can perform logical calculations on inputs—decisions based on and, or, not, and other such operations, and combinations of these operations—is a computer. The computers we’re used to thinking about use electrical voltages—high or low, on or off—rather than the presence or absence of biochemical transcription factors, but the conceptual framework is the same. Moreover, the underlying generality is the same. With the appropriate combination of logic elements, whether they’re electrical bits or genes, one can perform any computation, whether it’s compressing a digital video file or deciding whether conditions warrant germination of a seed … [T]he machinery of gene regulation makes every organism a powerful, versatile computer, capable of making decisions based on the diverse stimuli provided by its environment, and orchestrating behaviors that vary in time and space. This complexity doesn’t require thought, or central control, but rather comes from the nature of the genetic code itself, which contains genes as well as the means to regulate them. Again, we see self-assembly at work, with machineries that construct themselves.
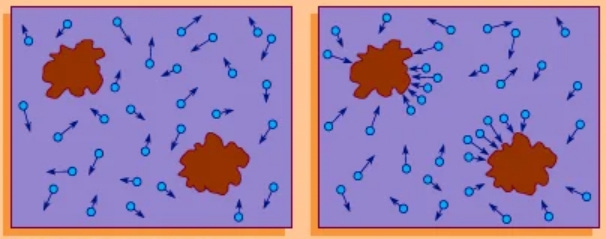
Finally, how do all these materials get close enough to each other to even start the process of binding molecules together? Surprisingly, it’s random, but a randomness (called “Brownian motion”) that facilitates molecule mergers in an environment that’s teeming with them all around.
When scientists first looked at small, inanimate objects in liquids under early microscopes, they saw them bouncing all around and didn’t know why. Albert Einstein figured out that the motion was caused by those small particles being pushed around by the impact of millions of smaller particles around them – the atoms and molecules – that were being jiggled about by heat energy. That motion is called “Brownian motion” after Robert Brown, the scientist who first studied the phenomenon in detail. And it’s this random “Brownian motion” that pushes small particles all over the place until they bump into something they can bond to or interact with.
As Johnjoe McFadden and Jim Al-Khalili write in their book Life on the Edge: The Coming Age of Quantum Biology, “free energy harvested from random molecular collisions (and their chemical reactions) is directed to maintain a body and make a copy of that body.”
As Parthasarathy describes it:
Beyond the obvious consequence that salts and sugars, lipids, proteins, and even whole cells are in constant agitation, Brownian motion illuminates a great many aspects of biology. First of all, it solves a nagging problem with our discussions of self-assembly in earlier chapters. As we’ve seen, proteins fold themselves into particular three-dimensional shapes, driven by physical interactions between the amino acids that make them up. Lego bricks, however, also have particular interactions between them, but a pile of bricks doesn’t spontaneously assemble itself into some form. Brownian motion explains the difference. Being small, the amino acid chain is in constant, vigorous motion. The molecule is always jiggling about, placing some amino acids in close proximity to others, then others, then others still, until it settles into a configuration in which sufficiently strong interactions lock it into place. Similarly, thermal energy drives the random motion of lipids; they find each other and assemble into a membrane. The recipe for self-assembly, therefore, is not merely physical interactions, but physical interactions together with Brownian motion. Similarly, gene expression and regulation also depend on Brownian motion. We’ve described transcription factor proteins binding to DNA, glossing over the question of how the proteins find their target DNA sequences. There’s no guiding hand or train track conveying them smoothly to their destination. Rather, buffeted by thermal energy, the proteins wander through the cellular space, colliding with all sorts of DNA regions and being held for a while by those they specifically match. As with self-assembly, this strategy for running a machine wouldn’t work for a macroscopic object—I can’t set my office key on the floor and hope it wanders off and finds the door lock—but it’s a great strategy in the microscopic world.
The strangeness of “Brownian motion” also delivers our thoughts:
How do the neurons manage to send and receive neurotransmitters across a chemical synapse? By doing nothing more than releasing these chemicals and then letting diffusion do the work of spreading them. Left alone, the molecules meander about the cleft, occasionally running into receptor proteins on the target cell that bind them and trigger a neural response. There’s no machinery needed— no nanoscale delivery van, no electromagnetic forces pushing the neurotransmitters along. The neurotransmitters are small, a nanometer or so in size, and their vigorous Brownian motion carries them a few tens of nanometers within about a microsecond … Every biological information pathway, however, is governed in some way or another by molecular flows, of which Brownian motion is an integral part, helping set the rate at which our brains function. The microsecond timescale of a chemical synapse is quite fast— obviously adequate for our needs. It’s interesting to contrast this, however, with the timescale of modern computers, which is around a nanosecond, a billionth of a second, per operation. My laptop operates far faster than my brain. Rather than relying on molecules, it harnesses the motion of far smaller electrons and, moreover, directly pushes them around with electric fields. My brain is relatively slow, but its neurons are much more interconnected than the transistors in my laptop’s central processing unit. The neural architecture enables a dazzling number of calculations to be performed in parallel among different sets of neurons at the same time rather than in a rigid, temporal sequence.
So our bodies are formed by the push and pull of electric charges and propensities to mesh or not with water, and the random battery of Brownian motion, in combinations honed by billions of years of evolution.
We are perhaps the most complex organic origami in the universe, and with the means of appreciating it.
I love most everything you do. You deserve bigger exposure -- hope it comes. Even stuff about which I know gets supplemented by stuff you know -- or the perspective is different enough that it causes me to think...always a good thing.
Many thanks for doing this.