


Origami, Ourselves – Part 1
We’re the products of the physics of biology.
In previous essays we’ve explored the importance of math to civilizational progress and the history of precision engineering in the manufacture of things. Now let’s appreciate the precision engineering that evolution has handed down to us in the form of life.
Raghuveer Parthasarathy has written a great book, So Simple a Beginning: How Four Physical Principles Shape Our Living World, that provides an overview of how the laws of physics and evolution combined over millions of years to create the interactions of particles we call life. And life’s engineering blueprint starts with DNA.
As Parthasarathy writes:
We can hold DNA in our hands and see it with our unaided eyes. This isn’t hard to do: a blender and some kitchen chemicals enable the extraction of DNA from a bowl of strawberries or a cup of peas. The recipe is roughly this: puree the fruits or vegetables in a blender, ripping their cells apart from each other. Add detergent to disintegrate cellular membranes. Sprinkle a dash of meat tenderizer or pineapple juice, supplying enzymes that digest proteins. DNA is now the only cellular component left intact. Add rubbing alcohol, which dissolves the protein pieces but not the DNA. The DNA clumps into long strands you can draw out with a toothpick, collecting a cloudy, stringy, white blob. That’s DNA.
But seeing DNA as a white blob would miss its miraculous context in its natural environment, starting with its unique twisted ladder shape, and that ladder’s steps that mark the path up to life. As Parthasarathy writes:
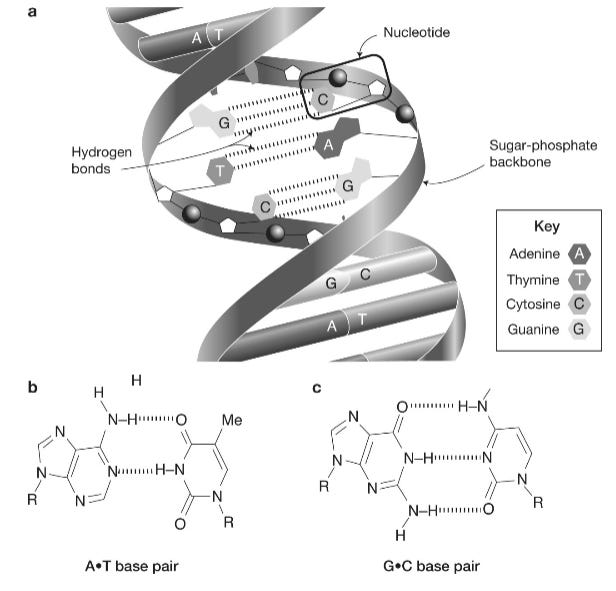
We’re all probably familiar with the “double helix” shape of the DNA, but at the end of each “base pair” that forms the steps on the ladder between the winding double helix is what’s called a nucleotide, which are the organic molecules that contain the code that, when replicated, sets up the structure of our bodies.
Computers calculate using switches called “bits,” with one “bit” being something that be either turned “on” or “off” and so transmit a code that contains, in computer terms, either a “1” or a zero. By adding more and more bits to a system, more and more combinations of 1’s and zeroes can be formed, producing more and more informational possibilities to transmit, to trigger more and more potential responses. (For an explanation of how that sort of system works to relay information, see this video here from the 2:22 to 13:19 minute mark.) Our DNA contains the same sort of code, but organically. As Parthasarathy explains:
How many bits is each person’s DNA sequence? Three billion symbols—that is, three billion As, Ts, Cs, and Gs—make up your DNA. We could make a dictionary like this, for example, to translate each symbol into a binary code: 00 = A 01 = T 10 = C 11 = G A sequence like ATTGC would be equivalent to 0001011110. Our three-billion-letter genome, therefore [nucleotide sequences of DNA] carries six billion bits of information—less than a gigabyte, and probably a small fraction of the storage capacity of the phone in your pocket. This presents a puzzle: I seem much more complex than my phone, despite my apparent paucity of information! We grapple with the concept of complexity through much of this book. For now, there’s a more immediate question: How does this abstract picture of codes and information relate to the stringy blob [mentioned] previously?
But how does this organic system move the information around? Computers run on electricity and are designed by engineers and produced in factories. But what propels and directs the parts of a living system? Parthasarathy writes:
Like all molecules, DNA consists of atoms, in its case atoms of carbon, hydrogen, oxygen, nitrogen, and phosphorus, held together by chemical bonds. The four symbols of the code mentioned above are really four assemblies of atoms, called nucleotides, stitched together to form a long chain … The interactions between atoms determine the structure of a molecule, and the structure of the molecule governs its function. Any of the four nucleotides, A, T, C, G, can be linked to any other to form a single strand of DNA. But the nucleotides also interact between strands, though more weakly, in a specific way: A and T bind together, as do C and G. (We say that A and T are complementary, as are C and G.) A single strand of DNA, for example, AGCCTATGA, binds its complementary strand, TCGGATACT … Interactions among the atoms drive the two DNA strands to wind around each other like twisting ivy, forming a double helix … The iconic double-helical form of DNA is functional as well as elegant. The two complementary strands convey redundant information: if I tell you the sequence of one strand, you know the other, since each nucleotide is the complement of its partner. This redundancy reveals how information can be transmitted from one cell to its two daughter cells as it divides: the DNA is unzipped and the complement of each original strand is synthesized, giving two DNA double helices from the original one.
As Johnjoe McFadden and Jim Al-Khalili write in their own excellent book Life on the Edge: The Coming Age of Quantum Biology, DNA contains a remarkable code that has been honed over millennia:
What tends to be emphasized in many accounts of the discovery of the genetic code is arguably a feature of secondary significance: that DNA adopts a double-helical structure. This is indeed remarkable, and the elegant structure of DNA has rightly become one of the most iconic images in science, reproduced on T-shirts and websites and even in architecture. But the double helix is essentially just a scaffold. The real secret of DNA lies in what the helix supports … What hadn’t escaped their notice was a crucial feature of the double helix, that the information on one of its strands—its sequence of bases—is also present as an inverse copy on the other strand: an A on one strand is always paired with a T on the other and a G is always paired with a C. The specific pairing between the bases on opposite strands (an A:T pair or a G:C pair) is actually provided by weak chemical bonds, called hydrogen bonds. This “glue” holding two molecules together is essentially a shared proton and is central to our story … [T]he weakness of the bonding between the paired DNA strands immediately suggested a copying mechanism: the strands could be pulled apart and each could act as a template on which to build its complementary partner to make two copies of the original double-strand. This is precisely what happens when genes are copied during cell division. The two strands of the double helix with their complementary information are pulled apart to allow an enzyme called DNA polymerase access to each separated strand. The enzyme then attaches to a single strand and slides along the chain of nucleotides, reading each genetic letter and, with almost unerring accuracy, inserting a complementary base into the growing strand: whenever it sees an A it inserts a T, whenever it sees a G it inserts a C, and so on until it has made a complete complementary copy. The same process is repeated on the other strand, giving rise to two copies of the original double helix: one for each daughter cell … The DNA pairing that holds the genetic code is rooted in the chemical bonds that hold the complementary bases together. As we have already mentioned, these bonds, called hydrogen bonds, are formed by single protons, essentially nuclei of hydrogen atoms, which are shared between two atoms, one in each of the complementary bases on opposite strands: it is these that hold the paired bases together. Base A has to pair with base T because each A holds protons at precisely the right positions to form hydrogen bonds with a T. An A base cannot pair with a C base because the protons would not sit in the right places to make the bonds … This proton-mediated pairing of nucleotide bases is the genetic code that is replicated and passed on at each generation. And this isn’t just a one-off transfer of information—like a coded message written on a “one-time” pad that is destroyed after use. The genetic code has to be continuously read throughout the life of the cell to direct the protein-making machinery to make the engines of life, enzymes, and thereby orchestrate all the other activities of the cell. This process is performed by an enzyme called RNA polymerase that, like DNA polymerase, reads the positions of those coding protons along the DNA chain. Just as the meaning of a message or the plot of a book is written into the position of letters on a page, so the positions of protons on the double helix determine the story of life.
How accurate is this natural system of transmitting information? As McFadden and Al-Khalili write:
We tend to take for granted the ability of living organisms to replicate their genomes accurately, but it is in fact one of the most remarkable and essential aspects of life. The rate of copying errors in DNA replication, what we call mutations, is usually less than one in a billion. To get some idea of this extraordinary level of accuracy, consider the one million or so letters, punctuation marks and spaces in this book. Now consider one thousand similarly sized books in a library and imagine you had the job of faithfully copying every single character and space. How many errors do you think you would make? … Imagine building a copying machine out of wet, squishy material. How many errors do you think it would make in reading and writing its copied information? Yet when that wet squishy material is one of the cells in your body and the information is encoded in DNA then the number of errors is less than one in a billion.
Most everyone has heard much of this before, but the beauty of the treatment of the subject in these books is that their authors explain to the reader how it is that the laws of physics dictate how DNA is formed from atoms and molecules, and how the ingredients of life “self-assemble” under the influence of forces discovered by Isaac Newton, Albert Einstein, Neils Bohr, and many other great scientists. The laws of physics are universal of course, or else they wouldn’t be physical “laws,” but still it’s fascinating to think that mere physical laws can produce such stunningly consistent results among millions of tiny parts. And what exactly are these precise physical laws that make this super-accurate system work? That will be the subject of the next essay.
Just think, how long did it take DNA polymerase to evolve? I have a definite intelligent design bias that is just reinforced by descriptions of irreducible complexity.
This is well done.
There is something I tell my medical students just to remind them of how it all comes together: All Medicine is Biology. All Biology is Chemistry. All Chemistry is Physics. And All Physics is Mathematics.
If you understand things at the base level, you can finally begin to understand all of the layers that sit on top of it all.
I love your writing -- so glad you do it.